FlushCache时间点
- 当memstore的字节数超过
hbase.hregion.memstore.flush.size 时, Region会发起一次异步的Flush Region操作, 这次Flush请求其实是放入到一个叫做MemStoreFlusher的队列中, 这个队列后面跟着一个线程池, 每个线程从队列中取Flush 请求, 然后每个FlushHandler并发地去进行对应的Flush操作. 注意这里有个参数可以控制FlushHandler的个数,叫做 hbase.hstore.flusher.count 。
- 创建snapshot的时候,需要Flush Cache。
- 关闭Region的时候,需要Flush Cache。
- 做Region的相关操作,例如Merge/Split操作时,需要FlushCache。
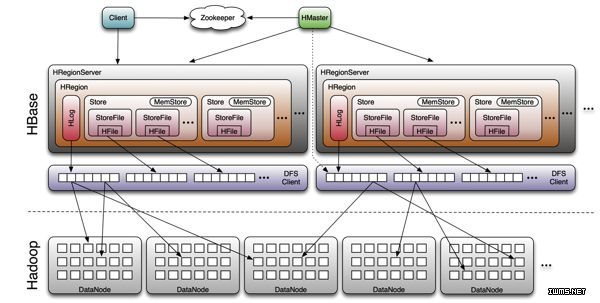 HBase FlushCache原理实现
HBase FlushCache原理实现
FlushCache流程
- 加锁;记录下当前的sequenceId,并备份Memstore的snapshot;放锁.
- 将各个store里面的memstore都导出到.tmp目录下的文件中.
- 善后处理. 例如将.tmp目录下的文件move到region目录下; 清理memstore中遗留的snapshot .
在这个过程中,有几个问题需要考虑:
Flush的各个步骤, 哪些步骤会影响读写操作? 那些步骤不会影响 ?
实际上,只有在第1步加锁拿sequenceId以及备份memstore的时候,是不让读写的(这里拿的锁是updatesLock.writeLock()) ,等放锁之后,memstore其实已经被拆分为两块内存了,一块是snapshot表示sequenceId之前的所有数据, 一块是kvset表示sequenceId之后的所有数据.如果这时候有一个MemstoreScanner需要读数据,那么需要把snapshot和kvset两个集合的数据做归并之后,按照顺序依次返回.
Flush和Compaction相互之间关系是什么?
首先FlushCache必定会导致storeFiles增多,storeFiles越多,compaction的压力越大。compaction操作越多,磁盘带宽压力越大,反过来也会影响flushCache的效率。因此,RegionServer做了一个限制就是当storeFiles个数超过blockingFilesCount的时候,可以让flush request最多等待blockingWaitTime时长,如果超过这个时长了, storeFiles的个数还是超过了blockingFilesCount,那就直接进行flush操作,不等了。
如果将时间轴按照第3步切分为两段,一段是之前,一段是之后,那么之前和之后,scanner操作有什么变化?
对于第3步之前,snapshot那部分数据是读内存,第3部之后,之前在内存中的那部分数据落到磁盘了。如果这期间有一个scan操作,那么需要在数据落到磁盘的时候,通知这个scan,告知下次读取数据,必须去磁盘中读数据,这个通知操作,就是通过ChangedReadersObserver来完成的,其实就是把之前打开的各种scanner都关闭掉,重新打开store中个各种scanner(参见 StoreScanner.resetScannerStack )。
Flush和Split有什么关系?
FlushCache会造成一个store落盘的总数据量增加,如果增加到一定阀值(默认是10G),这个store就会造成Region做split操作。对于一个Region中有多个store, 一般是让数据量最多的store去做splits。具体需要根据Region设置的 RegionSplitPolicy 来定。
来源:中国大数据

 注意:CPDA数据分析师全国各地人才培养合作,请咨询13001995337王女士
注意:CPDA数据分析师全国各地人才培养合作,请咨询13001995337王女士

