来源:CPDA数据分析师 刘程浩
这段时间忙了一阵子数据可视化的工作,有个感触挺深的:那就是一直以来我觉得比较入门级的描述统计,用的好还是可以帮助业务部门发现问题,甚至帮助我们的客户确定未来的发展方向的。
在写正文之前,我先说下我觉得比入门更高的数据分析,甚至觉得很高大上的数据分析是啥?我觉得就是依赖深奥的数学理论支撑的各种建模分析。
举例子来说,最简单的线性回归,略微复杂的时间序列回归模型ARIMA,带有可动态调整能力的状态空间方程、神经网络模型等等。
可能也和过去的业务特点有关,因为涉及到对未来的预测,因此这些建模分析工具需要捕捉到数据中的特征,并且用一些系数、参数、超参数来对过去的历史规律进行控制和表达。
不过,这些建模工具有个特点,就是一旦模型确定后(系数、参数、超参数确定),往模型里添加什么数据,跑出来的结果就牢牢的印上了历史规律的特点。这样一来对未来的预测往往就确定了。
打个形象的比喻,模型就好比模具。
像线性回归模型,无论是做何种线性变换进行数学公式的改变,经过历史数据的计算,一旦系数定了,那么模型想要表述的规律就定了,一点儿也不能改。
例如下面的月饼模具,因为是用木头雕刻的,所以一旦雕刻好,那么半径定了,花纹定了,无论你用啥糯米和颜料进行装饰,打出来的月饼就是那个样子。

而那种带有自动调节功能的模型,例如卡尔曼滤波用到的状态空间方程、各种神经网络模型,他们都有一些柔性,面对最后一批次的样本数据会调整自己的系数。这样一来模型的预测就会根据最后一段时间的数据规律或数据特征进行调整。
打比方的话,就像高分子模具例如硅胶磨具、或者再生活化一点诸如装水的气球。因为如果多装一点或少装一点原材料,模具会根据材料的多少发生形变,这样能够生产出形状略有差异的产品。

以上我说的建模的数据分析模型,背后都有比较深奥的数学知识在做支撑。
而且要想掌握和应用自如,还离不开各种分析软件、工具。自己还要学会对参数的调整、还要搞明白背后的数学逻辑后,懂得对模型进行选择和适配。因此对数学功底的要求比较高,自己也比较有面子。
但这些模型在使用起来的时候,和业务部门进行解释往往还比较吃力。
你比方说,什么叫系数矩阵的特征值,光特征值这个词要想和日常生活里的“特征”进行区别解释,就够你喝一壶的了。
除此之外,模型拟合出来的效果,乃至于预测出来的预测值,和实际业务进行对比起来,也有差异。
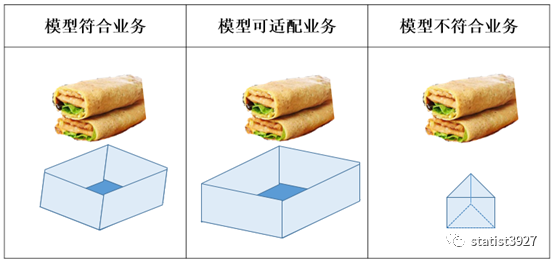
就如同下面的3个图中的盒子,用它们来比喻我们的模型;图中的煎饼,就好比我们的业务。
我们追求的是最左边的效果;然而实际上能做到中间的效果就是能让自己和业务部门都能接受的了;但是往往在建模分析的早期,效果是最右边图的呈现那样。
俗话说没有对比就没有收获,以上的感触和心得,是在我最近不断的使用数据可视化工具对数据进行描述统计分析的时候得到的。
描述统计分析一般就是分析个均值、方差、分布什么的。一般人看方差还看不出个所以然,所以很多人更喜欢看容易理解的均值。
如果单独看均值,说实话没有经过对比也是看不出什么东西的。但是如果拿到可对比的参考物前进行对比,那就有意义的多了。
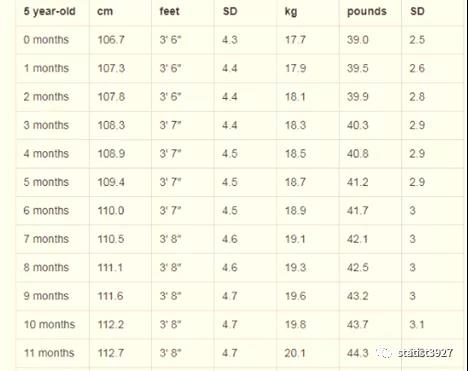
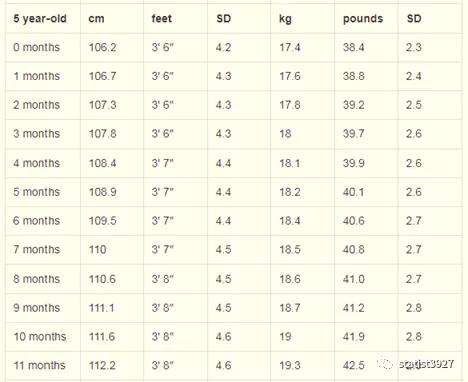
比方说,我在网上搜到了2015年日本厚生省统计的学龄前儿童的身高体征的均值,拿去我们家小孩所在的幼儿园家长群里,或者拿到我的亲戚、同事群里,好多人通过对比都说自己的孩子身高和体重超过了日本同龄人。
从而让我从很多实际样本中更加看清了网上“日吹”那帮人的奴颜媚骨。
例如下图中我截取的,
Japanese Boy
Japanese Girl
还有,例如2020年的疫情期间,通过国际第三方数据公司获取到的某些区域的网速热力图,放到一个时间轴上,就可以看出区域间的网速变化。
结合当时国内外相互借鉴的封城、居家办公、远程会议……等等措施,我们就能够很轻松得到一个结论:疫情改变了我们的网络使用强度和深度,并且随着疫情的控制这种网络使用模式并没有回退回过去最初的状态,并且需要国家和社会持续的加大互联网软硬件的建设投入。
这个结论拿到客户面前看,客户心里面对未来的预测,就相对容易多了。
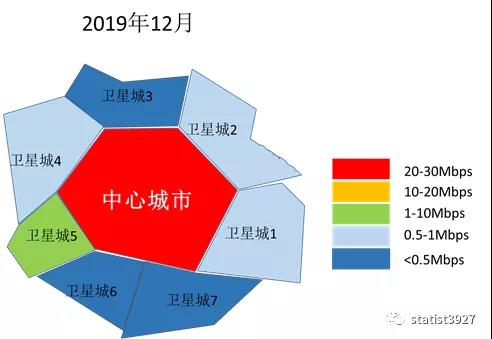
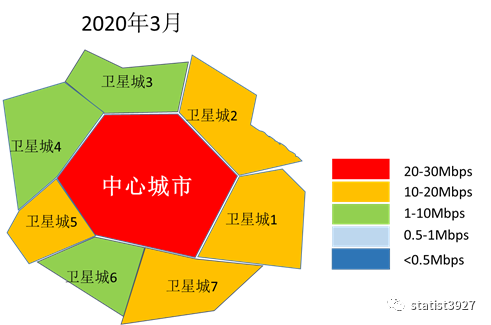
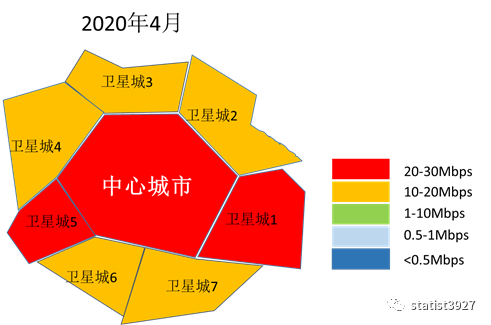
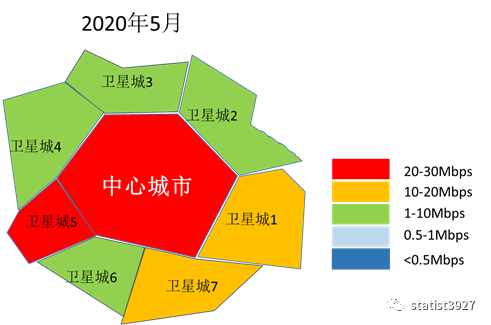
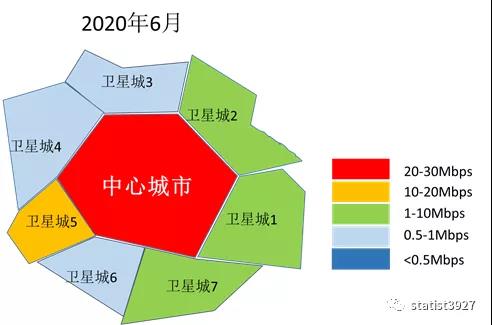
下面是我用比较粗糙的方法模拟出来的区域城市网络下载平均速率的热力图,从热力图中我们很容易向读者展示以下的信息:
- 中心城市,由于商业和人口都比较密集,因此大家对网络的使用强度和深度是刚性的,无论疫情变化如何。
- 对于卫星城市,由于封城和居家办公之前,商业和人口都没有那么密集,因此不同的卫星城市显然网络使用的强度和深度都是远不如中心城市的。
- 由于疫情的发展导致了封城和居家办公,人们的网络使用方式发生了重大改变,卫星城市的人们对网络使用的强度和深度都逐渐的接近中心城市。
- 随着疫情的被控制,虽然人们在中心城市和卫星城市之间的流动恢复了,但是人们在商业上的网络使用强度和深度却没有马上变回疫情之前的状态,反而缓慢的变化,并且在距离疫情初期较大距离处稳定下来。
- 因此,作为远程办公的设备商、网络服务提供的运营商,都不能认为疫情的控制代表了网络及其周边市场需求的昙花一现,而是要更加的提升自己的产品和服务的质量(用户体验),在新的对手出现之前进一步去争抢市场份额。


以上的数据可视化方法比较粗糙,如果大家能用支持热力图或区块图的软件或者工具,在一个固定的图上拖动时间轴看色块的变化,是很容易得到我刚才的结论的。
当然了,还有其他形式的描述统计分析我就不再在这里呈现了。
我觉得伟大的前人有句话说的好:问题表述清楚了,就解决了一半。
描述统计分析,就能轻松和直观地起到这个效果。

 注意:CPDA数据分析师全国各地人才培养合作,请咨询13001995337王女士
注意:CPDA数据分析师全国各地人才培养合作,请咨询13001995337王女士

